Introduction
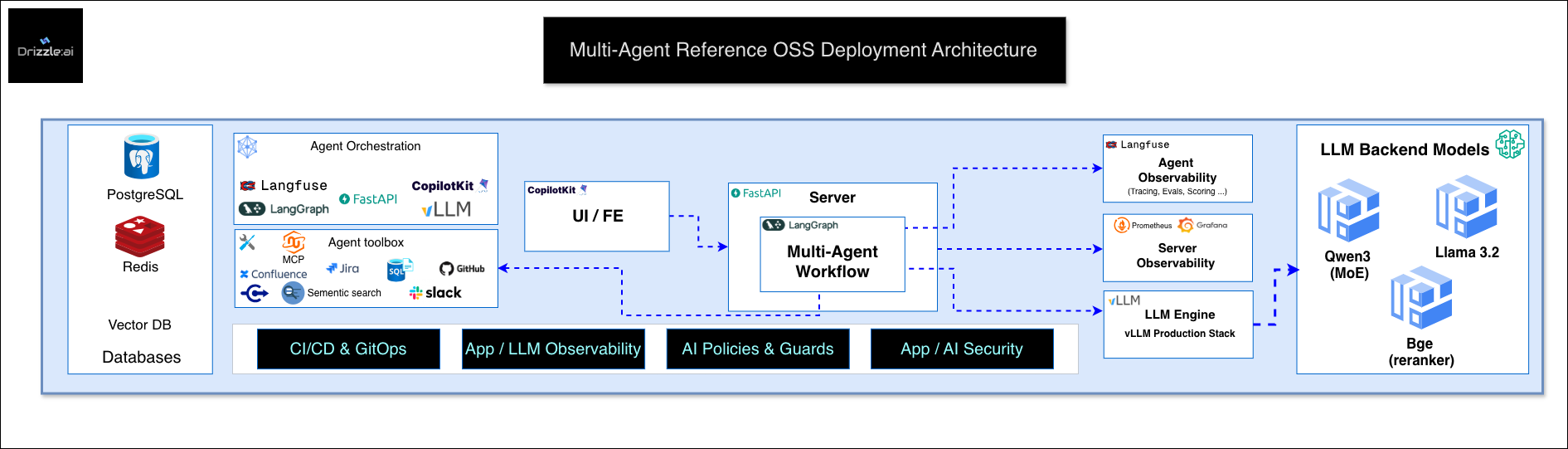
Drizzle:AI provides a proven, production-grade AI infrastructure for your cloud environment. Our open reference architecture is designed for multi-agent applications demanding low latency, high reliability, and strong security. Built on Kubernetes and powered by GitOps, Terraform, CI/CD pipelines, observability (O11y), and policy enforcement, this stack is validated across AWS, GCP, and Azure to ensure seamless deployment and operation.
System goals
- Mission-critical performance with vLLM and model caching.
- End-to-end observability: traces, metrics, evals, and logs.
- Strict security boundaries and auditability.
- Fast rollout by automation and blueprints.
- Open components. No lock-in.
High-level layout
- Data plane: UI, API server, agent runtime, vLLM engine, model backends, vector and relational stores.
- Control plane: CI/CD, GitOps, IaC, policy engine, secrets, monitoring, and dashboards.
Core components
Datastores
-
Relational Databases:
- PostgreSQL/MySQL for durable app state, runs, queues
- ACID transactions for policy configs and workflow data
- High-availability clustering with automated failover
-
Key-Value Stores:
- Redis clusters for low-latency caching
- Short-lived agent memory and conversation state
- Rate limiting and distributed locks
- In-memory performance with disk persistence
-
Vector Databases:
- Qdrant for production-grade vector search
- Optimized RAG indices and semantic routing
- Horizontal scaling with collection sharding
UI / Frontend
- CopilotKit for conversational UI and multi-agent UX patterns. Streams tokens, surfaces tool results, and exposes feedback hooks.
API Server
-
FastAPI service as the narrow waist. Responsibilities:
- AuthN/Z and request shaping.
- Session and tool routing.
- Back-pressure, timeouts, retries.
- Fan-out to workflows and vLLM.
Multi-Agent Workflow
-
LangGraph for deterministic graph execution:
- Nodes: planner, router, worker agents, critic, guard.
- Edges: success, fallback, escalate, terminate.
- Checkpoints in Postgres for resumability.
- Concurrency caps and circuit breakers.
Agent Toolbox
-
MCP (Model Context Protocol) as the unified tool interface:
- Protocol-level versioning and schema validation
- Automatic retry logic and fallback chains
- Tool discovery and capability negotiation
-
Enterprise connectors:
- Confluence: page search, content retrieval, metadata extraction
- Jira: issue query, creation, transition workflows
- GitHub: PR review, code search, repository operations
- Slack: message posting, channel management, thread context
- SQL: parameterized queries with read-only/read-write roles
-
Built-in utilities:
- Semantic search with re-ranking and relevance scoring
- File operations with content-type validation
- HTTP client with TLS verification and proxy support
- Templated SQL with injection prevention
-
Security and governance:
- Tool execution in isolated sandboxes
- Per-tool rate limits and concurrency caps
- Complete audit trail: inputs, outputs, execution time, caller identity
- Dynamic permission boundaries based on context and user role
Observability
-
Agent observability with Langfuse:
-
End-to-end trace visualization across multi-agent workflows
-
Token usage and cost tracking per agent, model, and session
-
Automated evaluation scoring with custom metrics
-
Prompt versioning and A/B test comparison
-
User feedback integration and annotation
-
Tracing across agents, tools, and models.
-
Evals and scoring hooks for regression detection.
-
-
Server observability with Prometheus + Grafana:
- Real-time performance metrics: TTFT (Time to First Token), TPOT (Time per Output Token), and end-to-end generation latency
- Request analytics: p50/p95/p99 latency distributions, throughput (requests/sec), and resource saturation
- SLO monitoring: error budget tracking, burn rate alerts, and automated incident detection
- Resource utilization: GPU/CPU usage, memory pressure, vLLM KV-cache hit rates, and request queue depth
- Infrastructure health: Kubernetes cluster metrics, node autoscaling events (Karpenter), and pod lifecycle tracking
LLM Engine
-
vLLM production infrastructure:
- Continuous batching and PagedAttention for maximum throughput
- Tensor parallelism and pipeline parallelism for large model distribution
- KV-cache optimization with prefix caching and memory pooling
- Multi-model serving with GPU memory isolation and fairness scheduling
- Quantization support (INT8, FP8, AWQ, GPTQ) for cost-efficient deployment
- Dynamic batching with preemption and priority queuing
-
Model portfolio (reference configuration):
- Qwen3 MoE: Complex reasoning, multi-step planning, and technical analysis
- Llama 3.2: General-purpose tasks, conversational flows, and structured outputs
- BGE reranker: Semantic relevance scoring and retrieval quality enhancement
- Hot-swappable model registry for A/B testing and gradual rollouts
-
Intelligent routing strategies:
- Static assignment: dedicated models per agent type or workflow stage
- Rule-based dispatch: task classification by complexity, domain, or latency requirements
- Adaptive routing: learned selection via telemetry feedback and cost-performance optimization
- Fallback chains: automatic degradation to lighter models under load or failure conditions
Security, Policies, and Guards
-
Policy enforcement layer:
- Pre-flight input validation: jailbreak detection, prompt injection scanning, and malicious pattern filtering
- Post-generation output guardrails: PII redaction, toxicity scoring, and sensitive data leakage prevention
- Tool authorization matrix: role-based ACLs with environment-specific permissions and data classification boundaries
- Compliance controls: content safety filters, export restriction enforcement, and regulatory policy adherence
-
Infrastructure security:
- Zero-trust networking: mTLS for all inter-service communication with mutual certificate verification
- Network microsegmentation: Kubernetes NetworkPolicies isolating workloads by security zone
- Identity and access: minimal RBAC with just-in-time privilege escalation and audit logging
- Secrets management: KMS-backed encryption with Secrets Store CSI driver and automatic rotation
- Supply chain security: signed container images, SBOM generation, and OPA admission policies
Platform Operations
-
Infrastructure as Code and GitOps:
- Terraform modules for cloud-native primitives: VPC, IAM, compute, storage, and managed services
- Declarative cluster configuration via Helm charts and Kustomize overlays
- Continuous reconciliation with Argo CD or Flux: automated drift detection and self-healing
- Environment promotion pipeline: dev → staging → production with policy checkpoints
-
Release engineering:
- Progressive delivery: blue/green deployments for zero-downtime updates, canary releases with automated traffic shifting
- Model validation: shadow traffic analysis, A/B testing with statistical significance checks
- Automated rollback: SLO-triggered reversion, error budget enforcement, and incident response integration
- Change management: approval workflows, deployment windows, and blast radius controls
Scaling model
-
Horizontal scaling:
- API and workflow tiers scale via replica sets with pod autoscaling (HPA/KEDA)
- Redis clusters with sentinel-managed failover and read replicas for cache distribution
- PostgreSQL with streaming replication, connection pooling (PgBouncer), and automated failover
- Vector databases scale through collection sharding with consistent hashing and replication
-
Vertical and GPU scaling:
- vLLM nodes scale by GPU count (tensor parallelism) and VRAM capacity (model size support)
- Intelligent model placement: scheduler packs models by KV-cache footprint and memory requirements
- Dynamic GPU allocation with Karpenter: just-in-time node provisioning and bin-packing optimization
- Multi-instance GPU (MIG) support for workload isolation and fractional GPU allocation
-
Throughput and capacity controls:
- Per-tenant queue admission with fair scheduling and priority inheritance
- Kubernetes priority classes for critical workflows and degraded-mode operations
- Adaptive load shedding: automatic request rejection when SLO burn rate exceeds thresholds
- Backpressure propagation from GPU layer to API gateway with graceful degradation
Reliability model
-
Fault tolerance and recovery:
- Checkpointed workflows in PostgreSQL enable atomic resume after crashes or preemption
- Distributed tracing for failure root cause analysis across multi-agent execution paths
- Automatic state reconciliation with idempotency keys and deduplication logic
-
Resilience patterns:
- Exponential backoff retries with jitter for transient failures
- Per-tool and per-model circuit breakers with configurable thresholds and half-open recovery
- Bulkhead isolation: resource pools prevent cascading failures across workflow stages
- Timeout hierarchies: request-level, tool-level, and model-level deadline enforcement
-
Proactive monitoring:
- Kubernetes liveness and readiness probes with custom health check endpoints
- Synthetic canaries: scheduled test workflows validating end-to-end functionality
- Chaos engineering: periodic fault injection to validate recovery automation
- Error budget tracking: automated release freezes when burn rate violates SLO policy
Security model
-
Network isolation:
- Private connectivity within VPC/VNet with no public internet exposure for LLM inference
- Service mesh (Istio/Linkerd) with mTLS enforcement and zero-trust segmentation
- Egress filtering: allowlist-based outbound connectivity with DNS policy enforcement
- DDoS protection and rate limiting at ingress with Web Application Firewall (WAF) integration
-
Identity and access management:
- SSO/OIDC federation with identity provider integration (Okta, Azure AD, Google Workspace)
- Fine-grained RBAC: per-tool scopes, data classification tags, and environment-specific policies
- Service account federation with workload identity and minimal privilege assignment
- Session management: token expiration, refresh policies, and concurrent session controls
-
Data sovereignty and compliance:
- Regional data residency enforcement: per-tenant pinning with geo-fencing controls
- Encryption at rest (AES-256) and in transit (TLS 1.3) for all data stores
- Data lineage tracking: payload classification, retention policies, and purge automation
- Compliance attestation: SOC 2, GDPR, HIPAA alignment with audit-ready evidence collection
-
Audit and forensics:
- Immutable audit logs: prompts, tool invocations, model responses, policy decisions, and user identity
- Tamper-proof storage with cryptographic signing and append-only log aggregation
- SIEM integration for security event correlation and threat detection
- Incident response playbooks with automated isolation and evidence preservation
Model and data governance
-
Version control and reproducibility:
- Prompts, agent definitions, and workflow graphs versioned in Git with review workflows
- Model artifacts tracked in registries with content-addressable storage and lineage metadata
- Dataset versioning with DVC or LakeFS: snapshots, branching, and rollback support
- Evaluation suite versioning synchronized with model releases
-
Testing and validation:
- Shadow deployments: parallel inference with production traffic for model candidate evaluation
- A/B testing framework: statistical significance checks and automated winner selection
- Pre-production validation: automated eval suites executed on every model promotion
- Regression detection: drift monitoring with alerts on quality degradation or behavioral changes
-
Continuous evaluation:
- Scheduled offline evals: periodic assessment against golden datasets and benchmark suites
- Online monitoring: real-time quality metrics from production traffic sampling
- Human-in-the-loop feedback: annotation workflows integrated with Langfuse and eval pipelines
- Automated retraining triggers based on performance thresholds and data distribution shifts
SLOs we typically enforce
-
Availability commitments:
- Control plane (API, workflow orchestration): ≥ 99.9% uptime with 43 minutes monthly error budget
- Data plane (vLLM inference, GPU workloads): ≥ 99.5% uptime with 3.6 hours monthly error budget
- Critical tool integrations: ≥ 99.5% success rate with automated failover to degraded modes
-
Quality and accuracy:
- Tool execution error rate: ≤ 1% over rolling 1-hour windows with alert escalation
- Evaluation score thresholds: domain-specific targets (e.g., ≥ 0.85 for RAG relevance, ≥ 0.90 for structured extraction)
- Hallucination detection: automated guardrail rejection rate ≤ 5% with manual review sampling
-
Cost efficiency:
- GPU utilization targets: ≥ 70% average with request batching and model co-location
- Token cost per session: tracked with budget alerts and spend anomaly detection
- Infrastructure cost allocation: per-tenant attribution with chargeback reporting
Deployment workflow with Drizzle:AI
-
Blueprint selection Choose single-tenant or multi-tenant, cloud Provider, GPU profile, and tool set.
-
Provisioning Terraform brings up cluster, networking, GPUs, storage, and observability.
-
Bootstrap GitOps installs vLLM, LangGraph, Langfuse, Prometheus/Grafana, secrets, and policy engine.
-
Integrations Wire MCP tools and agent accesses to your internal data sources such as Jira/Confluence/SQL and set RBAC.
-
Policies and SLOs Enable guards, define error budgets, and publish dashboards.
-
Cutover Canary traffic, shadow evals, promote on green SLO.
-
Operate We run it with you: upgrades, security patches, and capacity tuning.
Extensibility
- Plug in other base models or rerankers. vLLM hosts many concurrently.
- Add agents or tools by extending the LangGraph DAG.
- Swap vector stores or gateways behind clean interfaces.
- Bring your own eval harness. Langfuse supports custom scores.
What you get with Drizzle:AI
- Secure and scalable AI infra with GitOps, CI/CD, IaC, full observability, guardrails, and security automation.
- Fast rollout using tested blueprints and defined SLOs, with ongoing support.
- Open architecture with Cloud Native, Kubernetes, Terraform, GitOps, and vLLM.
Ready to Accelerate Your AI Journey?
The journey to building a multi-agent AI system doesn’t have to be fraught with obstacles. With a clear blueprint and a reliable partner, you can move toward the future with confidence.
Our reference architecture is our public answer to the question, “How do you build AI infrastructure right?” And the Drizzle:AI service is our promise to you that we will bring this answer to life.
Let’s connect and discuss how we can turn your grand AI vision into a tangible reality that drives business growth.












Stop Building Infra. Start Delivering AI Innovation.
Your AI agents and applications are ready, but infrastructure complexity is creating bottlenecks. We eliminates these obstacles with enterprise-grade AI infrastructure that seamlessly integrates into your existing cloud environment—transforming months of deployment work into days of rapid delivery.