
Table of Contents
Open Table of Contents
Introduction
Productionizing AI infrastructure can often be overly complex. Between deploying an experimental Large Language Model (LLM) and serving it at scale, there is a maze of infrastructure decisions, framework incompatibilities, and operational challenges that can delay deployments by months. KServe’s mission is to eliminate this complexity. It is a standardized, cloud-native platform designed for deploying Generative AI (Gen AI) and machine learning (LLM) LLMs on Kubernetes (K8S), whether you are serving traditional ML models or the latest frontier LLM.
Originally known as KFServing, KServe has evolved into the Cloud Native Computing Foundation’s (CNCF) reference AI Inference implementation, trusted by leading organizations running AI at scale.
Whether you are a data scientist looking to deploy your latest ML experiment, a DevOps engineer building scalable ML infrastructure, or a decision-maker evaluating AI infrastructure platforms, KServe provides the production-grade foundation you need without vendor lock-in.
What You’ll Learn in This Blog
In this comprehensive guide, you’ll discover:
- The “Last Mile” Problem: Understanding why model serving presents unique infrastructure challenges that go far beyond simple API deployment
- Foundational Introduction to KServe: What KServe is, its evolution from KFServing, and the key benefits that set it apart from other serving solutions
- KServe Design and Architecture: Deep dive into core design principles, control and data planes, deployment modes (Standard vs. Knative), inference protocols, and the LLMInferenceService resource
- Hands-On Lab: Step-by-step walkthrough of deploying Gemma 3 on Google Kubernetes Engine using KServe’s Standard mode with Gateway API and KEDA autoscaling
By the end, you’ll understand why KServe has become the open-source standard for model serving—and how to use it to accelerate your own AI deployments.
The “Last Mile” Problem: Why Model Serving/Inference is a Unique Challenge
When you train an ML model, the next critical step is to make it accessible to your end users through a process called serving. In simpler terms, serving means loading your trained model into an inference server and exposing an API endpoint that applications or users can call to get predictions. This is where your model transitions from an experimental artifact to a production service that delivers real business value.
- Process of using a trained model to make predictions or generate outputs based on new inputs
- Supports real‑time tasks like text generation, translation, and summarization
- Essential for responsive, production‑grade applications
- Requires building a scalable platform to handle high demand and low latency
You might wonder why model serving requires specialized tools like KServe. After all, can’t we just wrap our model in a Flask API and call it a day? The reality is that production model serving presents a set of challenges that go far beyond simply calling model.predict().
First, there’s the performance challenge. Inference workloads have unique characteristics—they’re often bursty, require low latency, and need to handle concurrent requests efficiently. A simple Flask server will buckle under production traffic, leading to poor user experiences and wasted resources.
Then there’s the scalability problem. Production models need to scale up and down based on demand, sometimes dramatically. Traditional (Kubernetes) autoscaling approaches based on CPU metrics don’t work well for inference workloads, which are often GPU-bound and have different resource utilization patterns.
Model versioning presents another hurdle. Organizations need to serve multiple versions of the same model simultaneously for A/B testing, canary deployments, or gradual rollouts. Managing this complexity manually is error-prone and time-consuming.
Next, there’s the observability challenge. Unlike traditional web services, model inference requires specialized monitoring. You need to track not just latency and throughput, but also model-specific metrics like prediction drift, feature importance, and confidence scores.
The cold start problem becomes particularly acute with LLMs. Large language models can take several minutes to load into GPU memory, making standard container starting approaches impractical. Users won’t wait 8 minutes for your model to “wake up.” This requires local LLM caching on the nodes to solve this known ML/LLM challenge.
Security and compliance present another layer of complexity, especially for LLM deployments. You need a specialized AI/LLM API gateway that handles authentication and authorization, but also implements guardrails to prevent prompt injection attacks, data leakage, and generation of harmful content. Without proper safeguards, your LLM endpoints become potential security vulnerabilities and compliance nightmares.
KServe addresses all these challenges out of the box, providing a production-ready foundation for model serving that would otherwise require months of custom engineering.
But what is KServe after all?
I. Foundational Introduction to KServe
1. What is KServe?
From the KServe official documentation, KServe is defined as:
“Standardized Distributed Generative and Predictive AI Inference Platform for Scalable, Multi-Framework Deployment on Kubernetes”
What makes KServe particularly powerful is its ability to serve any framework—TensorFlow, PyTorch, XGBoost, Scikit-learn, and more—through a unified interface. It’s designed from the ground up to handle the unique challenges of production inference workloads, from autoscaling to versioning to monitoring.
KServe began its journey as KFServing, a project under the Kubeflow umbrella aimed at solving the ML model’s serving problem on Kubernetes. As the project matured and gained adoption, it became clear that its value extended beyond just Kubeflow users.
In 2021, the project was renamed to KServe and became a standalone CNCF (Cloud Native Computing Foundation) project. This change reflected its broader mission to serve as the standard for model serving on Kubernetes, regardless of whether you’re using Kubeflow or not.
Today, KServe is widely adopted across industries - see the industry adopters here: - and has become the reference implementation for model serving on Kubernetes. Its CNCF status ensures it remains vendor-neutral, community-driven, and aligned with the broader cloud-native ecosystem.
- Latest Version: v0.16.0
- Status: CNCF Incubating Maturity Level
- CNCF Page: cncf.io/projects/kserve
- GitHub: github.com/kserve/kserve
- Documentation: kserve.github.io/website
- Community Slack: #kserve on Kubernetes Slack
- Original Creator: Dan Sun
2. Key Benefits that Set KServe Apart
While many excellent serving and inference projects exist in the industry, several key features and benefits led us at Drizzle AI Systems to select KServe for our production-ready AI infrastructure mission:
-
Kubernetes-Native Architecture: KServe is built from the ground up for Kubernetes, leveraging native Kubernetes objects like Pods and Deployments, also K8S constructs like CRDs and operators. This deep integration means it works seamlessly with existing Kubernetes tooling and processes, rather than fighting against them.
-
Cloud-Agnostic Portability: Deploy anywhere—whether you’re on AWS, Azure, GCP, on-premises, or hybrid environments, KServe provides consistent behavior and identical APIs across all platforms. This eliminates vendor lock-in and enables seamless workload migration between cloud providers.
-
Unified Platform: A single platform for both Generative AI (mainly LLMs) and Predictive AI (mainly traditional ML frameworks like PyTorch, TensorFlow, etc) inference on Kubernetes. This eliminates the operational complexity of managing separate serving infrastructures for different AI workloads, providing consistent APIs, monitoring, and deployment patterns across your entire model portfolio and teams.
-
Production-Grade Scaling: Based on Keda and Knative, KServe automatically handles traffic spikes,
scale-to-zero(Knative option), and manage multi models efficiently. -
LLMs and ML Framework Agnostic Excellence: KServe’s unified interface seamlessly supports multi-LLM frameworks (Hugging Face, vLLM, etc) and Multi-ML frameworks (TensorFlow, PyTorch, XGBoost, Scikit-learn, etc) through a single, consistent API.
-
Advanced Inference Patterns: Built-in support for
OpenAI-Compatible APIs,Canary deployments,A/B testing,InferenceGraphfor model ensembles, multi-node inference, intelligent routing and density packing usingModelMesh… etc -
Optimized Inference Performance: KServe delivers great performance through intelligent resource management and advanced caching strategies. Its KV Cache Offloading capabilities optimize GPU memory utilization, while model caching dramatically reduces cold start times from 15-20 minutes to under 1 minute for large language models.
-
Seamless Operations - Production monitoring, logging, low-latency prediction serving for real-time applications and observability out of the box.
-
Enterprise Security: KServe provides
Envoy AI Gatewayintegration, which is an enterprise-grade API management and routing for AI workloads that ensures authentication, authorization, and rate limiting features out-of-the-box, meeting the strict security requirements of production environments. -
Proven at Scale: Organizations like Bloomberg, IBM, and Nvidia trust KServe for their production workloads, validating its reliability and performance under real-world conditions.
Now that you understand what KServe is and why it’s useful for production AI workloads, it is the right time now to dive into how it actually works.
II. KServe Design and Architecture Concepts
1. Core Design Principles
KServe’s power lies in three fundamental design principles that make production model serving accessible without sacrificing flexibility:
-
Declarative Simplicity: Model deployment inputs are defined in a main YAML configuration (
InferenceService), eliminating the need to manually configure K8S objects like containers, pods, services, etc. KServe starts from theInferenceServiceand orchestrate everything else automatically. -
Extending Kubernetes: KServe extends K8S through purpose-built Custom Resources (CRDs) designed specifically for inference workloads. This deep integration means you get cloud-native scalability, reliability, and observability patterns that work seamlessly with your existing K8s infrastructure—without needing to become a Kubernetes expert.
-
Runtime Flexibility Through Abstraction: KServe’s pluggable architecture separates the “what” from the “how” of model serving. Choose the optimal inference engine for your workload—vLLM for LLMs, TorchServe for PyTorch, TensorRT for NVIDIA optimization, or bring your own custom runtime—all while maintaining a consistent API and operational model.
2. KServe Generative Inference Architecture
The following figure describes the main components of the GenAI Inference architecture:
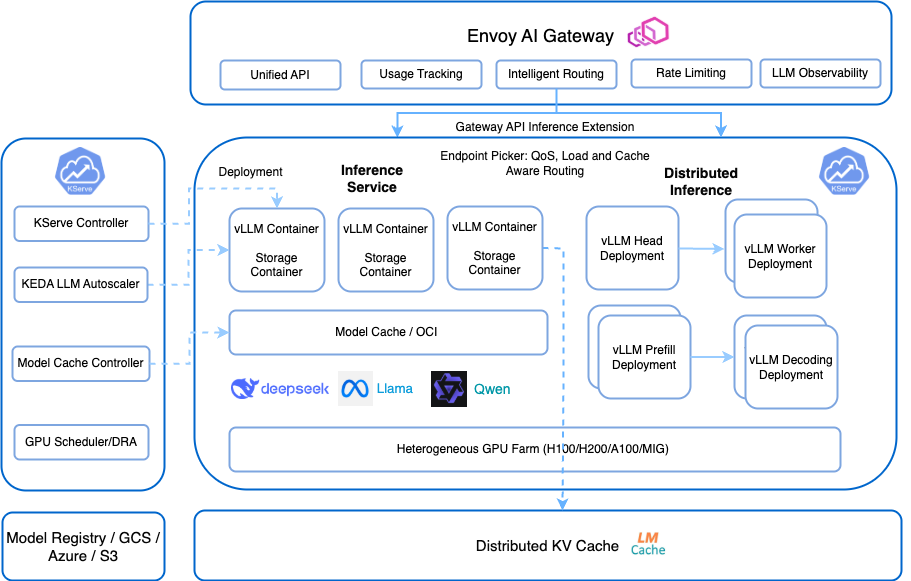
Key Component:
-
Envoy AI Gateway: The top-level, unified API gateway that provides several routing features (smart request distribution based on model requirements), security features (like rate limiting, auth/z, etc) and monitoring features (like LLM Observability and model usage metering) -
Gateway API Inference Extension: The official Kubernetes Gateway implementation, that provides enhanced routing capabilities such as endpoint picker, load-aware routing, cache-aware routing, etc. -
KServe Controller: more details in the next section. -
Inference Service Deployment: handle LLM standard K8S deployments controlling thevLLMcontainers, storage containers, model caching / OCI (caches models across K8S nodes). -
Distributed Inference: For larger models requiring distributed processing vLLM deployment (e.g.vLLM head,vLLM workers,vLLM prefilling,vLLM decoding,..) -
Infrastructure Components: The foundation layer orchestrates a sophisticated hardware ecosystem designed for maximum flexibility and performance:- Heterogeneous GPU Farms(H100, H200, A100, MIG)
- Distributed KV Cache: A cluster-wide shared memory system for model key-value pairs, across all inference pods, dramatically reducing redundant computations and improving response times for similar queries.
- Model Registry / Hugging Face Hub / GCS / Azure / S3; providing deployment flexibility without vendor lock-in.
This architecture showcases how KServe unifies specialized components into a production-grade platform. Each layer tackles specific LLM serving challenges, from intelligent request routing and dynamic resource allocation to hardware acceleration and cache optimization, creating an end-to-end solution that transforms complex infrastructure into simple, declarative configurations.
3. KServe Control and Data Planes
KServe consists of two main components:
- Control Plane
The brain of the KServe operations; it manages the complete inference service lifecycle, orchestrates with Kubernetes APIs, handles resource provisioning, etc. Operating independently from the data plane, this architectural ensures clean concerns.
It onsists of several components such as Controller Manager, LocalModel Controller, Networking Components, Autoscaling Components, and much more.
- Data Plane
The data plane is designed to be independent from the control plane, focusing purely on inference execution, using inference API that is independent of any specific ML/DL framework and model server.
We’ll be publishing deep-dive articles on the control plane and data plane components in our blog. Stay tuned!
4. KServe Deployment Modes
- Standard Mode (Raw K8S Deployment mode): Standard Deployment mode uses standard Kubernetes resources and is recommended for most production environments.
- Knative mode: Leverages Knative Serving for event-driven, scale-to-zero capabilities.
Standard Mode
This is the recommended deployment mode for LLM Serving. In this mode KServe uses standard Kubernetes objects for maximum control, and it is the recommended for most production environments.
The following diagram shows how this standar deployment mode (with Gateway API) working.

Standard Mode Architecture Characteristics:
- Native K8S Deployments (Deployment, Service, …)
- Gateway API: Leverages K8S Gateway API for advanced traffic management (recommended way)
- Kubernetes Ingress Fallback: Supports Kubernetes Ingress (e.g. Nginx) but with limited functionality
- Horizontal Pod AutoScaler (HPA) + Optional KEDA: Uses HPA for basic scaling, with KEDA for advanced metrics
- ✅ Production environment requiring high availability, or omplex networking
- ✅ Multi-tenant environments with strict isolation requirements
- ✅ Applications requiring persistent connections or streaming
- Knative Mode:
In this mode, KServe leverages Knative for serverless capabilities including scale-to-zero, this mode is ideal for dynamic workloads requiring resource efficiency.
The following diagram shows how the KServe Knative mode works:
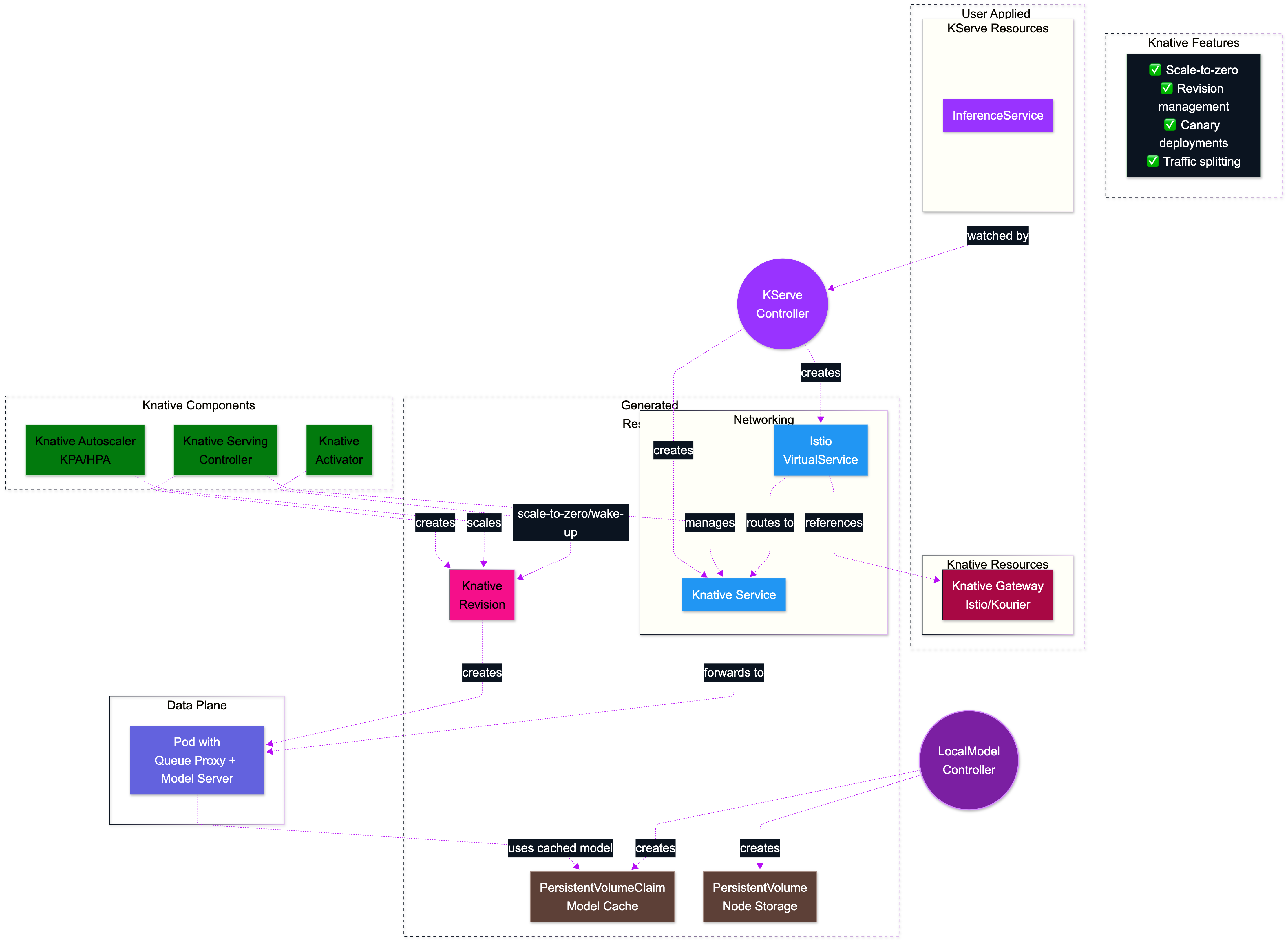
Knative Mode Architecture Characteristics:
- Knative Resources (Knative Service and Revision)
- Knative Gateway (Istio or Kourier)
- Scale-to-Zero: Scale down to zero replicas when no traffic
- Queue Proxy: Each pod includes a Knative queue proxy for metrics and request handling
- Revision Management: Automatic deployment versioning and traffic splitting features.
- ✅ Cost efficiency is a priority benefiting from scale-to-zero
- ✅ Unpredictable traffic patterns
- ✅ Burst traffic use case where instant scaling is required
- ⚠️ Cold Start Latency: Initial requests may experience higher latency
- ⚠️ Resource Overhead: Queue proxy containers add resource overhead
- ⚠️ Networking Dependencies: Requires Istio or Kourier for networking
5. The KServe Inference Protocols
KServe supports two protocol versions for model inference, each designed to meet different operational needs:
KServe V1 Protocol (Legacy) The V1 protocol provides a standardized prediction workflow across all model frameworks. While still supported for backward compatibility, it offers basic inference capabilities with a simple request/response pattern.
KServe V2 Protocol: The Open Inference Protocol (Recommended) The V2 protocol, also known as the Open Inference Protocol, sets the modern standard for model serving. KServe’s V2 protocol improves upon several limitations found in the V1 protocol, delivering better performance and enhanced compatibility across various model frameworks and servers. It supports both HTTP/REST and gRPC interfaces, providing flexibility in implementation.
The V2 protocol is recommended for all new deployments and serves as the foundation for KServe’s advanced features. For more details about the V2 Protocol please refer to the official documentation
6. The LLMInferenceService
It is a Kubernetes Custom Resource Definition (CRD) introduced in KServe. The LLMInferenceService provides the standard pattern on deploying and managing LLM inference workloads on Kubernetes.
While KServe has traditionally used the InferenceService CRD for serving machine learning models, the platform now adopts a dual-track architecture to address the distinct requirements of modern AI workloads:
InferenceService: The original CRD optimized for Predictive AI workloads. It excels at serving traditional ML models from frameworks. While still capable of serving LLMs, it’s designed primarily for conventional machine learning inference patterns.
LLMInferenceService: A purpose-built CRD specifically engineered for GenAI workloads and LLMs. This specialized resource addresses the unique challenges of LLM serving, including:
- Distributed multi-node inference for models that exceed single-GPU capacity
- Prefill-decode separation for optimized token generation
- Advanced routing strategies for disaggregated serving architectures
- Integrated support for KV cache management and sharing
- Native OpenAI-compatible API endpoints
This architectural separation enables KServe to deliver LLM-specific optimizations and features without introducing unnecessary complexity to the traditional InferenceService API.
At this stage, you might already feel saturated with the conceptual terminologies. So, let’s switch things up a bit and get hands-on with KServe. In the next section, you’ll be deploying and serving Gemma 3 with vLLM in KServe, demonstrating how to utilize GPU resources in KServe on Google Kubernetes Engine (GKE). Let’s do it!
III. Lab: Deploy Your First KServe Inference Service on GKE
In this hands-on lab, you’ll learn how to serve a GenAI LLM on Kubernetes using KServe’s recommended deployment pattern (Raw K8S Deployment) with a Gateway API for routing and an LLMInferenceService. We will use Google Kubernetes Engine (GKE) and Gemma 3.
1. GKE Setup
First, we’ll provision a GKE cluster. An Autopilot cluster is ideal as it manages the underlying nodes, allowing you to focus on the application.
- Ensure you have a
gcp projectwith billing enabled and theGKE APIactivated. - Ensure you have the following tools installed on your workstation:
- gcloud CLI- kubectl- helm- Set the default environment variables:
export PROJECT_ID=$(gcloud config get project)export REGION=us-central1 # update to suit your needsexport CLUSTER_NAME=dais-kserve-raw-demo # updated for this lab- Create a GKE Autopilot cluster with the necessary permissions for networking:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --location=$REGION \ --project=$PROJECT_ID \ --labels=created-by=dais,guide=kserve-the-ultimate-guide
# Configure kubectl to communicate with your new clustergcloud container clusters get-credentials ${CLUSTER_NAME} \ --region ${REGION} \ --project ${PROJECT_ID}You should see an output similar to my outout below:
kubeconfig entry generated for dais-kserve-raw-demo.NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS STACK_TYPEdais-kserve-raw-demo us-central1 1.33.5-gke.1201000 136.119.xxx.xxx ek-standard-8 1.33.5-gke.1201000 3 RUNNING IPV42. Recommended KServe Setup with Gateway API, and KEDA
In this section, we will manually install the required components for KServe’s Standard deployment mode. We will install Gateway API, KEDA for autoscaling, Envoy Gateway for traffic management, and KServe with LLMInferenceService support.
Resources to be installed
- Infrastructure Components for Kserve Standard
- KEDA (for Standard KServe autoscaling)
- KEDA OpenTelemetry Addon (for Standard KServe autoscaling)
- Infrastructure Components for LLMInferenceService:
- External Load Balancer (MetalLB for local clusters)
- Cert-Manager
- Gateway API CRDs
- Gateway API Inference Extension CRDs
- Envoy Gateway
- Envoy AI Gateway
- LeaderWorkerSet (multi-node deployments)
- GatewayClass
- Gateway
- KServe Components
- KServe CRDs and Controller (Standard)
- LLMInferenceService CRDs and Controller
Follow the quick start guide at https://kserve.github.io/website/docs/getting-started/quickstart-guide to deploy and test KServe locally.
2.1. Define Component Versions
The versions of the components we are about to install.
export ISTIO_VERSION=1.27.1export KSERVE_VERSION=v0.16.0export GATEWAY_API_INFERENCE_EXTENSION_VERSION=v1.1.0export CERT_MANAGER_VERSION=v1.16.1export GATEWAY_API_VERSION=v1.4.0export KEDA_VERSION=2.18.1export ENVOY_GATEWAY_VERSION=v1.5.0export ENVOY_AI_GATEWAY_VERSION=v0.3.0export LEADER_WORKER_SET_VERSION=v0.6.22.2. Install Core Dependencies
We’ll begin by installing the foundational networking and security components.
- Install Gateway API CRDs, and Inference Extension
Gateway API provides a standard, vendor-agnostic way to expose network services. We’ll also install the Kubernetes Standard Inference Extension for LLM-specific routing capabilities.
echo "Installing Gateway API CRDs..."kubectl apply -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.4.0/standard-install.yaml
echo "Installing Gateway API Inference Extension CRDs..."kubectl apply -f https://github.com/kubernetes-sigs/gateway-api-inference-extension/releases/download/v1.1.0/manifests.yaml- Install Cert-Manager
Cert-Manager is required to automate the management and issuance of TLS certificates for KServe’s webhooks.
# Add the Jetstack Helm repositoryhelm repo add jetstack https://charts.jetstack.io --force-updatehelm repo update
# Install Cert-Managerhelm install \ cert-manager jetstack/cert-manager \ --namespace cert-manager \ --create-namespace \ --version v1.16.1 \ --set crds.enabled=true
echo "Successfully installed Cert-Manager"You can verify the installation by checking the cert-manager pods (your output may vary):
Context "gke_project-xxxxxxxxx_us-central1_dais-kserve-raw-demo"Active namespace is "cert-manager".> kubectl get poNAME READY STATUS RESTARTS AGEcert-manager-76d8bd58dd-8w8b9 1/1 Running 0 5m25scert-manager-cainjector-77c548b55f-4c46f 1/1 Running 0 5m25scert-manager-startupapicheck-8qntf 1/1 Running 3 (66s ago) 4m30scert-manager-webhook-85b85dfff8-drqts 1/1 Running 0 5m25s2.3. Install KEDA for Autoscaling
KEDA (Kubernetes Event-driven Autoscaling) is the recommended autoscaling solution for KServe in Standard mode.
# Add the KEDA Helm repositoryhelm repo add kedacore https://kedacore.github.io/chartshelm repo update
# Install KEDAhelm install keda kedacore/keda --version 2.18.1 --namespace keda --create-namespace --wait
echo "Successfully installed KEDA"
# Install OpenTelemetry Operator for KEDAhelm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-chartshelm repo update
helm install my-opentelemetry-operator open-telemetry/opentelemetry-operator \ -n opentelemetry-operator-system --create-namespace \ --set "manager.collectorImage.repository=otel/opentelemetry-collector-contrib"
# Install KEDA OpenTelemetry Addonhelm upgrade -i kedify-otel oci://ghcr.io/kedify/charts/otel-add-on \ --version=v0.0.6 --namespace keda --wait \ --set validatingAdmissionPolicy.enabled=false
echo "Successfully installed KEDA OpenTelemetry Addon"Example of the expected output when installing KEDA:
Update Complete. ⎈Happy Helming!⎈NAME: kedaLAST DEPLOYED: Tue Nov 18 17:24:40 2025NAMESPACE: kedaSTATUS: deployedREVISION: 1DESCRIPTION: Install completeTEST SUITE: NoneNOTES::::^. .::::^: ::::::::::::::: .:::::::::. .^.7???~ .^7????~. 7??????????????. :?????????77!^. .7?7.7???~ ^7???7~. ~!!!!!!!!!!!!!!. :????!!!!7????7~. .7???7.7???~^7????~. :????: :~7???7. :7?????7.7???7????!. ::::::::::::. :????: .7???! :7??77???7.7????????7: 7???????????~ :????: :????: :???7?5????7.7????!~????^ !77777777777^ :????: :????: ^???7?#P7????7.7???~ ^????~ :????: :7???! ^???7J#@J7?????7.7???~ :7???!. :????: .:~7???!. ~???7Y&@#7777????7.7???~ .7???7: !!!!!!!!!!!!!!! :????7!!77????7^ ~??775@@@GJJYJ?????7.7???~ .!????^ 7?????????????7. :?????????7!~: !????G@@@@@@@@5??????7:::::. ::::: ::::::::::::::: .::::::::.. .::::JGGGB@@@&7::::::::: ?@@#~ P@B^ :&G: !5. .Kubernetes Event-driven Autoscaling (KEDA) - Application autoscaling made simple.
_ _ _ _ ?@@#~ ___ | |_ ___| | __ _ __| | __| | ___ _ __ P@B^ / _ \| __/ _ \ | / _` |/ _` |/ _` |___ / _ \| '_ \ :&G: | (_) | || __/ | | (_| | (_| | (_| |___| (_) | | | | !5. \___/ \__\___|_| \__,_|\__,_|\__,_| \___/|_| |_| , .Successfully installed KEDA OpenTelemetry Addon~2.4. InstallLeaderWorkerSet, Envoy Gateway and Envoy AI Gateway
-
LeaderWorkerSet is required for multi-node deployments.
-
Envoy Gateway provides a cloud-native gateway implementation that works well with KServe. We’ll also install the AI Gateway for LLM-specific routing capabilities.
-
Envoy AI Gateway requires Envoy Gateway
version 1.5.0or higher. For the best experience while trying out AI Gateway, we recommend using the latest version as shown in the commands below. -
(Optional) Depending on the additional features you want to handle by the Envoy A Gateway (like rate limiting or InferencePool), you need to pass additional addon values files to modify the Envoy Gateway installation. Currently, supported addons are:
# Create the namespace for KServe componentskubectl create namespace kserve --dry-run=client -o yaml | kubectl apply -f -
# Install LeaderWorkerSet for multi-node deploymentskubectl apply -f https://github.com/kubernetes-sigs/lws/releases/download/v0.6.2/manifests.yaml
echo "Successfully installed LeaderWorkerSet"
# Install Envoy Gatewayhelm install eg oci://docker.io/envoyproxy/gateway-helm \ --version v1.5.0 \ -n envoy-gateway-system \ --create-namespace \ --wait
echo "Successfully installed Envoy Gateway"
# Create GatewayClasskubectl apply -f - <<EOFapiVersion: gateway.networking.k8s.io/v1kind: GatewayClassmetadata: name: envoyspec: controllerName: gateway.envoyproxy.io/gatewayclass-controllerEOF
# Create Gatewaykubectl apply -f - <<EOFapiVersion: gateway.networking.k8s.io/v1kind: Gatewaymetadata: name: kserve-ingress-gateway namespace: kservespec: gatewayClassName: envoy listeners: - name: http protocol: HTTP port: 80 allowedRoutes: namespaces: from: All infrastructure: labels: serving.kserve.io/gateway: kserve-ingress-gatewayEOF
# Install Envoy AI Gateway CRDshelm install aieg-crd oci://docker.io/envoyproxy/ai-gateway-crds-helm \ --version v0.3.0 \ --namespace envoy-ai-gateway-system \ --create-namespace
# Install Envoy AI Gatewayhelm install aieg oci://docker.io/envoyproxy/ai-gateway-helm \ --version v0.3.0 \ --namespace envoy-ai-gateway-system \ --create-namespace
# Configure Envoy Gateway for AI Gateway integration
kubectl apply -f "https://raw.githubusercontent.com/envoyproxy/ai-gateway/v0.3.0/manifests/envoy-gateway-config/redis.yaml"kubectl apply -f "https://raw.githubusercontent.com/envoyproxy/ai-gateway/v0.3.0/manifests/envoy-gateway-config/config.yaml"kubectl apply -f "https://raw.githubusercontent.com/envoyproxy/ai-gateway/v0.3.0/manifests/envoy-gateway-config/rbac.yaml"
# Enable Gateway API Inference Extension support for Envoy Gatewaykubectl apply -f "https://raw.githubusercontent.com/envoyproxy/ai-gateway/v0.3.0/examples/inference-pool/config.yaml"kubectl rollout restart -n envoy-gateway-system deployment/envoy-gateway
echo "Successfully installed Envoy AI Gateway"ensure components are deployed and healthy and surface any installation errors
Tip: Run the commands below to validate installations, check rollout status, and collect logs for troubleshooting.
2.5. Install KServe with LLMInferenceService
Now install KServe’s CRDs and controller configured for Standard mode, and ensure the LLMInferenceService CRDs are available. The commands below will:
- Install KServe CRDs and controller via Helm
- Set the default deployment mode to “Standard”
- Restart the controller so the change takes effect
# Install KServe CRDs firsthelm install kserve-crd \ oci://ghcr.io/kserve/charts/kserve-crd \ --version v0.0.16 \ --namespace kserve \ --wait
# Install the KServe controllerhelm install kserve \ oci://ghcr.io/kserve/charts/kserve-resources \ --version v0.0.16 \ --namespace kserve \ --wait
# Update KServe configuration for Standard modekubectl patch configmap inferenceservice-config -n kserve --type merge -p '{"data":{"deploy":"{\"defaultDeploymentMode\":\"Standard\"}"}}'
# Restart the KServe controller to apply the configuration changeskubectl rollout restart deployment/kserve-controller-manager -n kserve
echo "Successfully installed KServe in Standard mode"2.6. Verify Installation
Ensure all components are running correctly before proceeding.
# Check that the KServe controller manager is runningkubectl rollout status deployment/kserve-controller-manager -n kserve
# Verify that the required ServingRuntimes are availablekubectl get ServingRuntimes -n kserve
# Check that KEDA is runningkubectl rollout status deployment/keda-operator -n kserve
# Check that Envoy Gateway is runningkubectl rollout status deployment/envoy-gateway -n envoy-gateway-system
# Check that Envoy AI Gateway is runningkubectl rollout status deployment/ai-gateway-controller -n envoy-ai-gateway-system
# Check that LeaderWorkerSet is runningkubectl rollout status deployment/lws-controller-manager -n lws-system3. Deploy Gemma 3 with LLMInferenceService
With the infrastructure in place, we can now deploy the Gemma 3 model using the LLMInferenceService.
3.1. Create Hugging Face Secret
You need a Hugging Face token to download the Gemma 3 model.
- Generate a Hugging Face access token with
readpermissions. - Ensure you have accepted the terms of use for the Gemma 3 model on Hugging Face.
# Create a namespace for our inference servicekubectl create namespace dais-kserve-demo
# Replace XXX with your actual Hugging Face tokenexport HF_TOKEN="XXX"
# Create the secret in Kuberneteskubectl apply -f - <<EOFapiVersion: v1kind: Secretmetadata: name: hf-secret namespace: dais-kserve-demotype: OpaquestringData: hf_api_token: ${HF_TOKEN}EOF3.2. Deploy the LLMInferenceService
Create the LLMInferenceService manifest. This resource is specifically designed for LLM workloads and integrates with KEDA for autoscaling.
kubectl apply -f - <<EOFapiVersion: llm.serving.kserve.io/v1alpha1kind: LLMInferenceServicemetadata: name: huggingface-gemma3 namespace: dais-kserve-demospec: predictor: nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 cloud.google.com/gke-accelerator-count: "1" model: modelFormat: name: huggingface args: - --enable_docs_url=True - --model_name=gemma3-4b-it - --model_id=google/gemma-3-4b-it env: - name: HF_TOKEN valueFrom: secretKeyRef: name: hf-secret key: hf_api_token resources: limits: cpu: "6" memory: 24Gi nvidia.com/gpu: "1" requests: cpu: "6" memory: 24Gi nvidia.com/gpu: "1" autoscaling: minReplicas: 1 maxReplicas: 3 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 - type: Resource resource: name: memory target: type: Utilization averageUtilization: 80EOF3.3. Create an HTTPRoute to Expose the Service
Create an HTTPRoute to connect our Gateway to the predictor Service created by KServe.
kubectl apply -f - <<EOFapiVersion: gateway.networking.k8s.io/v1beta1kind: HTTPRoutemetadata: name: gemma3-route namespace: dais-kserve-demospec: parentRefs: - name: eg namespace: envoy-gateway-system rules: - matches: - path: type: PathPrefix value: / forwardTo: - serviceName: huggingface-gemma3-predictor port: 8080EOF4. Test the Inference Service
First, wait for the model pod to be in a Running state.
kubectl get pods -n dais-kserve-demo -wNext, get the external IP address of the Envoy gateway, which is our entry point.
export INGRESS_IP=$(kubectl get svc eg-envoy-gateway -n envoy-gateway-system -o jsonpath='{.status.loadBalancer.ingress[0].ip}')export SERVICE_URL="http://${INGRESS_IP}"echo "Inference Service is available at: ${SERVICE_URL}"Now, send a request to the OpenAI-compatible endpoint provided by the vLLM server runtime.
curl -X POST "${SERVICE_URL}/v1/chat/completions" \-H "Content-Type: application/json" \-d '{ "model": "gemma3-4b-it", "messages": [ { "role": "system", "content": "You are a helpful AI Infra expert" }, { "role": "user", "content": "What is KServe with Standard mode and KEDA?" } ], "max_tokens": 100, "stream": false}'You can also access the interactive Swagger UI for testing at ${SERVICE_URL}/docs.
4.1. Test Autoscaling
To test the autoscaling capabilities provided by KEDA, you can generate load on the service:
# Install hey if you don't have itgo install github.com/rakyll/hey@latest
# Generate loadhey -z 2m -c 10 -m POST -d '{ "model": "gemma3-4b-it", "messages": [ { "role": "user", "content": "What is the meaning of life?" } ], "max_tokens": 50}' -H "Content-Type: application/json" "${SERVICE_URL}/v1/chat/completions"
# Watch the replicas scale upkubectl get pods -n dais-kserve-demo -w5. Clean Up
Delete the GKE cluster to remove all resources created in this lab.
gcloud container clusters delete ${CLUSTER_NAME} \ --location=$REGION \ --project=$PROJECT_ID \--quiet
echo "Cluster ${CLUSTER_NAME} deleted successfully"Conclusion: From Theory to Production
KServe provides the powerful, open-source building blocks for enterprise-grade model serving. It addresses the unique challenges of production inference workloads, from scalability to versioning to observability, all while maintaining a simple, consistent interface that works across frameworks and deployment environments.
But building, securing, and observing a complete, production-ready AI platform around KServe is a complex engineering challenge. It requires expertise in Kubernetes, MLOps, security, observability, and infrastructure management expertise that many organizations struggle to acquire and maintain.
At Drizzle AI Systems (a.k.a DAIS), we specialize in building these platforms, turning open-source components like KServe into battle-tested, managed AI infrastructure. We’ve helped organizations across industries move from experimenting with models to running them confidently in production.
Ready to embrace the power of KServe in your production AI infrastructure?
Schedule a Free 30-Minute Strategy Session with our AI infrastructure experts. In this consultation, you’ll get:
- ✅ Architecture review of your current or planned KServe deployment
- ✅ Custom recommendations for your specific use case (LLMs, traditional ML, or hybrid)
- ✅ Cost optimization strategies for GPU utilization and autoscaling
- ✅ Security and compliance guidance for production AI workloads
- ✅ Clear roadmap from proof-of-concept to production-ready infrastructure
Explore Our Open-Source Contributions
We believe in contributing back to the community. Check out our GitHub organization for more AI Infra extensions, deployment templates, and production-ready configurations:
Visit Drizzle AI Systems on GitHub →
Share This Guide
Found this guide helpful? Share it with your team:
Questions or feedback? Reach out to us at contact@drizzle.systems or connect with me on LinkedIn.
Get Involved with KServe
Interested in contributing to the future of model serving? The KServe community welcomes developers, data scientists, and infrastructure engineers of all experience levels.
Ways to Get Involved:
- 📚 Documentation: Help improve guides and tutorials
- 🐛 Bug Reports: Report issues or inconsistencies you encounter
- 💡 Feature Requests: Suggest enhancements for the project
- 🔧 Code Contributions: Submit pull requests for bug fixes or new features
- 💬 Community Support: Answer questions on Slack or GitHub Discussions
- 🎤 Share Your Story: Present your KServe use case at community meetings
Join the Community:
- KServe GitHub Repository
- Community Slack (#kserve channel)
- Community Meetings
- Contribution Guidelines
Whether you’re fixing a typo in the docs or architecting a major feature, your contributions help make KServe better for everyone.
Frequently Asked Questions (FAQ)
What is the difference between Standard mode and Knative mode in KServe?
Standard mode uses native Kubernetes resources (Deployments, Services, HPA) and is recommended for production LLM workloads requiring stable endpoints and complex networking. Knative mode leverages Knative Serving for serverless capabilities including scale-to-zero, making it ideal for cost optimization with unpredictable traffic patterns. Standard mode offers more control and stability, while Knative mode provides better resource efficiency.
Does KServe support GPU acceleration?
Yes, KServe fully supports GPU acceleration for inference workloads. It works seamlessly with NVIDIA GPUs, including A100, H100, L4, and others. You can specify GPU requirements in your InferenceService or LLMInferenceService resource definitions, and KServe will automatically schedule pods on GPU-enabled nodes.
How does KServe handle model versioning and A/B testing?
KServe provides built-in support for canary deployments and traffic splitting, allowing you to deploy multiple versions of a model simultaneously and gradually shift traffic between them. This enables safe A/B testing and gradual rollouts of new model versions without service interruption.
What monitoring and observability features does KServe provide?
KServe integrates with standard Kubernetes observability tools and provides metrics compatible with Prometheus and Grafana. It exposes model-specific metrics like prediction latency, throughput, and error rates. When combined with tools like the Envoy AI Gateway, you can also track LLM-specific metrics like token usage and prompt characteristics.
Can I use KServe with my existing ML models?
Yes, KServe supports a wide range of ML frameworks including TensorFlow, PyTorch, Scikit-learn, XGBoost, and custom models. For LLMs, it supports popular frameworks like Hugging Face Transformers, vLLM, and TensorRT-LLM. You can also create custom ServingRuntimes for specialized frameworks.
What is the LLMInferenceService and when should I use it?
LLMInferenceService is a specialized CRD designed specifically for serving Large Language Models. It provides LLM-specific features like distributed multi-node inference, prefill-decode separation, KV cache management, and native OpenAI-compatible APIs. Use it instead of the standard InferenceService when deploying LLMs for better performance and easier configuration.
How does KServe compare to solutions like vLLM or TGI?
This is a key concept: KServe is not a replacement for these, it’s an orchestrator for them. vLLM and TGI are high-performance inference servers. KServe provides the production-grade platform around them, managing:
-
The deployment as a Kubernetes-native resource (LLMInferenceService)
-
Network routing (via Gateway API)
-
Autoscaling (via KEDA)
-
Observability and logging
In our lab, the LLMInferenceService automatically uses a vLLM-based runtime to serve the Gemma 3 model.
What are the security best practices for KServe deployments?
Key security best practices include: enabling authentication and authorization through the Envoy AI Gateway, using secrets management for API tokens (like Hugging Face tokens), implementing network policies to restrict pod-to-pod communication, using RBAC for controlling access to KServe resources, and enabling TLS for encrypted communication. For LLM deployments, also implement prompt injection protection and content filtering.
How much does KServe cost?
KServe itself is completely free and open-source under the Apache 2.0 license. You only pay for the underlying infrastructure costs (Kubernetes cluster, GPUs, storage, networking) from your cloud provider. There are no licensing fees, vendor lock-in, or usage-based charges for KServe itself.
Can KServe scale to zero to save costs?
Yes, when using Knative mode, KServe can scale deployments down to zero replicas when there’s no traffic, significantly reducing infrastructure costs. However, this comes with cold start latency when the service needs to wake up. For LLM workloads where cold starts can take several minutes, Standard mode with a minimum replica count is often preferred.

