Your API Gateway is Failing Your LLMs. Here’s Why.
You’ve done the hard part. You’ve deployed your first set of large language models on Kubernetes, your teams are excited, and the C-suite is ready for the AI revolution. But then, the user complaints begin. Responses are slow, users see random errors, and your cloud bill is spiraling. You check your dashboards, and your expensive GPUs are either completely overloaded or sitting frustratingly idle.
What went wrong?
The culprit is often hiding in plain sight: your traditional API gateway and load balancer. The tools that have served your microservices faithfully for years simply were not designed for the unique, demanding, and frankly bizarre traffic patterns of LLM inference.
The “Smart” Model on a “Dumb” Network
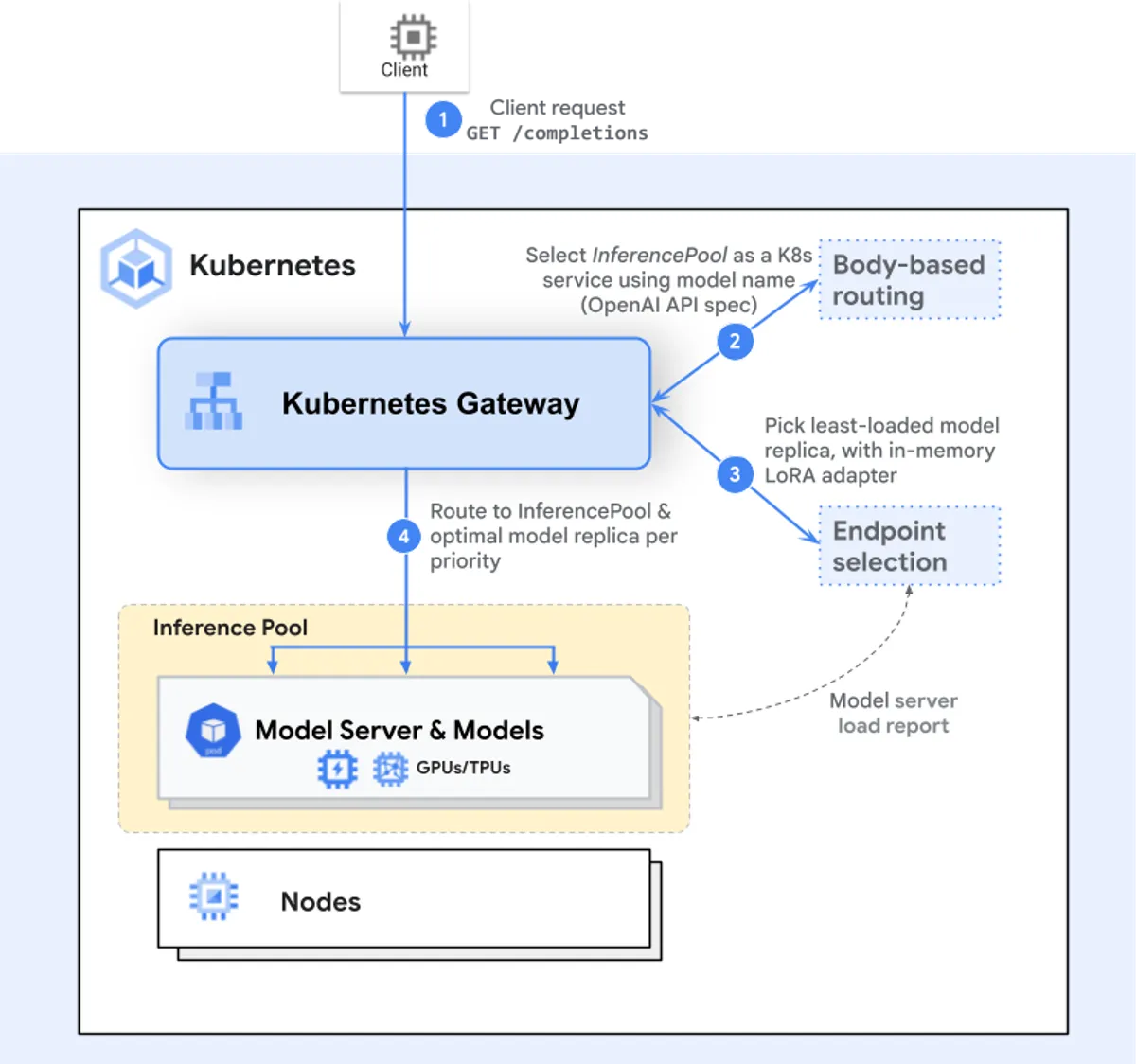
The core issue is that LLM inference is not a simple, stateless request. A model’s performance on any given query depends heavily on what’s already in the GPU’s memory—specifically, the KV Cache. This cache stores the results of previous calculations, and routing a new request to a backend that already has the relevant cache (a “warm” backend) is orders of magnitude faster than sending it to one that doesn’t.
Your traditional round-robin or least-connection load balancer knows nothing about this. It sees a new request and happily sends it to the next available server, which might be completely “cold” or, worse, already struggling with a long processing queue. This inefficient routing leads directly to:
- High Latency: Every “cold” request forces expensive re-computation, making your application feel sluggish.
- Wasted GPU Cycles: Your GPUs spend more time re-calculating data than serving unique requests, driving up costs for no reason.
- Cascading Errors: Routing new requests to already overloaded backends increases errors and degrades performance for everyone.
Beyond routing, traditional gateways fail to address other LLM-specific needs, like preserving Server-Sent Events (SSE) for streaming responses or implementing token-aware rate limiting instead of simple request-based limits.
The Solution: An LLM-Aware Inference Gateway
To solve this, you don’t need a better load balancer; you need a smarter one. You need an LLM-Aware Inference Gateway.
This new layer of the stack acts as an intelligent traffic cop designed specifically for AI workloads. It goes beyond simple routing by understanding the context of each inference request. A true Inference Gateway provides:
Intelligent, Policy-Based Routing
Instead of random distribution, it uses an Endpoint Picker policy. It inspects the request body to identify the target model and then makes a routing decision based on real-time metrics from the backend inference servers. It can ask questions like:
- Which backend already has the relevant KV cache?
- Which backend has the shortest processing queue?
- Which backend has the required LoRA adapter already loaded in memory?
Model-to-Backend Mapping
It uses a declarative, Kubernetes-native approach (like a Custom Resource Definition) to map user-facing model names (e.g., “llama3-8b-chat”) to the specific group of backend pods that serve it. This allows platform teams to manage a complex pool of models as a centralized service.
Native LLM Protocol Handling
It correctly manages streaming responses, token-based billing logic, and sophisticated retry strategies with backoff to create a resilient and user-friendly experience.
Stop Building a Bottleneck. Build an Enterprise LLM Gateway.
Building an LLM-Aware Gateway from scratch is a massive undertaking. It’s a core component of a production-ready AI platform—and it’s exactly what we’ve built into the Drizzle:AI Platform Accelerator.
Our platform provides a centralized, secure, and cost-effective Enterprise LLM Gateway that solves these networking challenges from day one. We handle the complexity of intelligent routing, multi-model serving, and GPU optimization so you can focus on building the AI applications that drive your business forward.
Stop letting your network be the bottleneck for your AI innovation. Book a free strategy call with our platform architects today, and let’s design an inference platform that actually performs.

